从零实现高性能 CPU 矩阵乘法:逼近 OpenBLAS 的优化之路
本文最后更新于 2025年12月29日 凌晨
在大模型推理引擎开发中,矩阵乘法(GEMM)是最核心的计算密集型算子。虽然可以直接调用 OpenBLAS、MKL 等成熟库,但在实际工程中存在一些问题:
- 库体积问题:OpenBLAS 占用数十 MB,影响推理引擎的部署体积
- 线程池冲突:OpenBLAS 内部维护线程池,与 OpenMP 混用时会产生资源竞争
- 学习价值:手写 GEMM 是理解计算机体系结构的绝佳实践
本文记录了我从零实现一个高性能 CPU 矩阵乘法的完整过程,最终在单核条件下达到 OpenBLAS 82% 的性能,而在 24 核并行时超越 OpenBLAS 6%。具体的性能测试结果参见:https://github.com/tianyuxbear/matmul-cpu
问题定义:
所有矩阵均为 行主序(Row-Major) 存储。
测试环境:
1 | |
理论峰值性能[1]:
1 | |
理论峰值内存带宽[1]:
1 | |
最终性能:
矩阵规模 M = N = K = 4096,2 次预热(warmup)轮次,10 次正式基准测试(benchmark)轮次。
| 配置 | 实现 | Peak GFLOPS | Avg GFLOPS | vs OpenBLAS |
|---|---|---|---|---|
| 单核 | 本文实现 | 110.74 | 109.37 | 82.4% |
| 单核 | OpenBLAS | 132.88 | 132.62 | — |
| 24核 | 本文实现 | 2010.61 | 1909.40 | 106% |
| 24核 | OpenBLAS | 1914.91 | 1796.69 | — |
第一部分:理论基础
1.1 Roofline 模型:计算瓶颈 vs 访存瓶颈
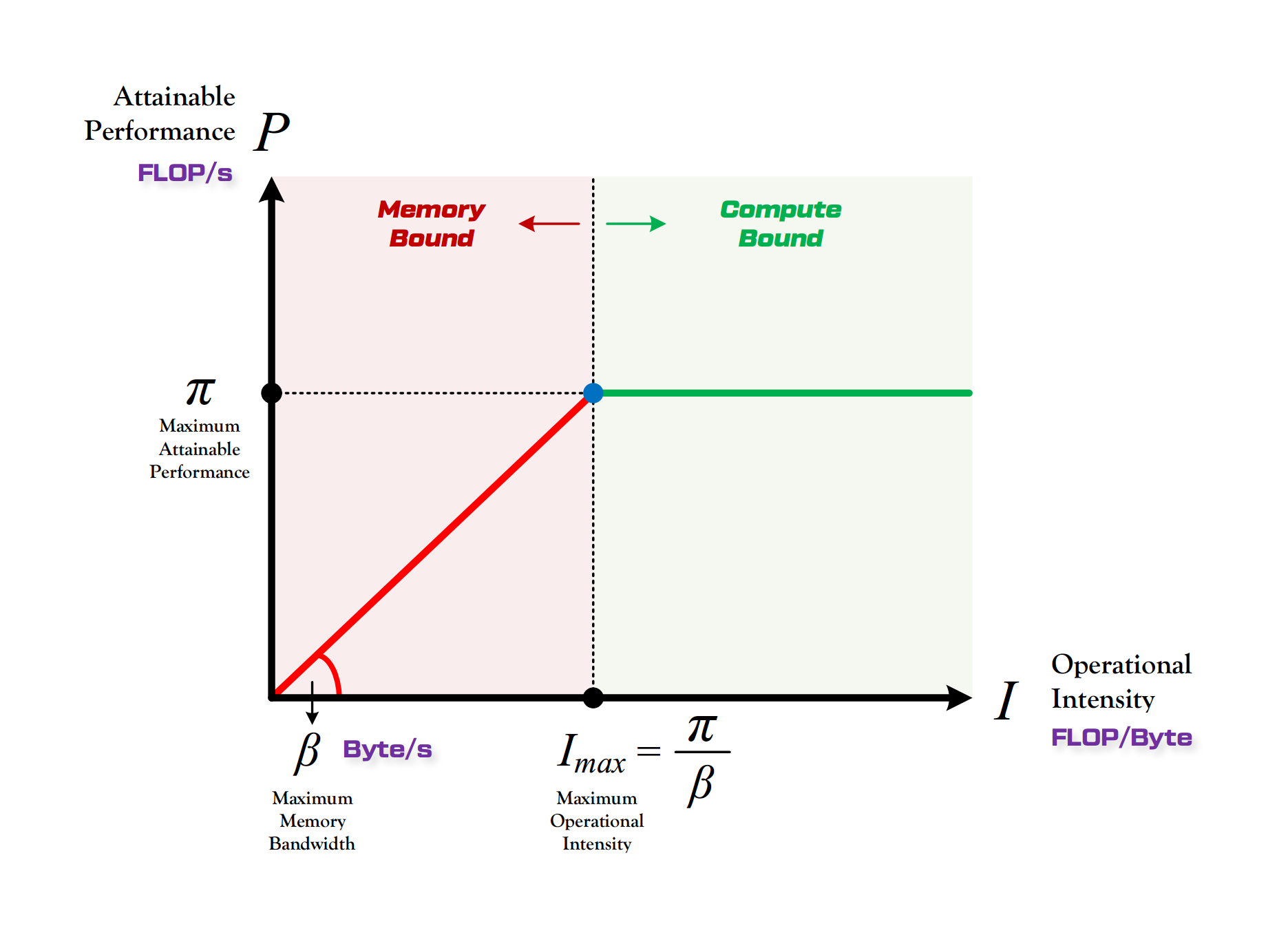
- 算力 π:也称为计算平台的性能上限,指的是一个计算平台倾尽全力每秒钟所能完成的浮点运算数。单位是
FLOPS或FLOP/s[2]。
- 带宽 β:也即计算平台的带宽上限,指的是一个计算平台倾尽全力每秒所能完成的内存交换量。单位是
Byte/s[2]。
- 计算强度上限 Imax:两个指标相除即可得到计算平台的计算强度上限。它描述的是在这个计算平台上,单位内存交换最多用来进行多少次计算。单位是
FLOPs/Byte[2]。
注:这里所说的“内存”是广义上的内存。对于 CPU 计算平台而言指的就是真正的内存;而对于 GPU 计算平台指的则是显存[2]。
1.2 对朴素实现的观察
1 | |
计算量与访存量分析:
1 | |
与 Roofline 拐点对比:
1 | |
问题总结:
| 问题 | 原因 | 影响 |
|---|---|---|
| 计算访存比极低 | 无数据复用,每个元素重复加载 | 受限于内存带宽 |
| 无 SIMD | 标量操作 | 浪费 16 倍算力 |
| 无指令并行 | 循环依赖(C[i][j] 累加) | 流水线停顿 |
理想情况:
1 | |
优化的核心目标: 通过分块和数据复用,将计算访存比从 0.25 提升到接近 O(N),让算法从 Memory Bound 转变为 Compute Bound。
第二部分:优化策略全景
🚀 GEMM 优化技术栈演进路线
1 | |
Level 3 优化技术:
- Multi-level cache blocking:根据 L1/L2/L3 容量设计分块参数(MC, NC, KC),精确控制数据驻留层级
- Data packing:将分块数据重排为连续内存布局,提升 cache line 利用率和预取效率
- Register blocking:设计 14×32 微内核,最大化 ZMM 寄存器复用,采用外积累加消除数据依赖
基线测试结果
| Kernel | 描述 | Peak GFLOPS | Avg GFLOPS |
|---|---|---|---|
core_v1_avx2 | AVX2 向量化内层循环 | 6.42 | 6.35 |
core_v2_avx512 | AVX-512 向量化内层循环 | 7.12 | 7.07 |
core_v3_block | 简单 2D 循环分块 | 19.74 | 19.73 |
注意:AVX-512 相比 AVX2 提升很小,因为此时内核是访存瓶颈——单纯增加计算吞吐而不优化内存访问模式,收益微乎其微。
源码链接
core_v1_avx2:https://github.com/tianyuxbear/matmul-cpu/blob/master/src/core/matmul_v1_av2.cppcore_v2_avx512:https://github.com/tianyuxbear/matmul-cpu/blob/master/src/core/matmul_v2_avx512.cppcore_v3_block:https://github.com/tianyuxbear/matmul-cpu/blob/master/src/core/matmul_v3_avx512_block.cpp
- SIMD向量化一条指令可以处理 8/16 个float,提高了计算吞吐。
- 基础分块提升局部性的本质:通过减小工作集大小,让数据驻留在更快的缓存层级中,被多次复用后再换出。
第三部分:基础分块优势
3.1 朴素版本的问题
1 | |
内存访问分析:
| 矩阵 | 每次内循环读取 | 总读取次数 | 总数据量 |
|---|---|---|---|
| A[i] | K 个元素 | M × N 次 | M × N × K |
| B[j] | K 个元素 | M × N 次 | M × N × K |
问题所在:
1 | |
B 矩阵的每一行被读取了 M 次,但由于 B 太大无法全部放入缓存,每次都要从主存重新加载!
3.2 分块版本的优势
1 | |
假设:M=N=K=1024,TILE=16,每个元素 4 字节
朴素版本内存访问:
处理整个矩阵:
- A 总读取:M × N × K × 4 bytes = 1024 × 1024 × 1024 × 4 = 4 GB
- B 总读取:M × N × K × 4 bytes = 4 GB
- 总计:8 GB 数据传输
分块版本内存访问:
处理一个 16×16 的 C 子块:
- 需要 A 的 16 行:16 × 1024 × 4 = 64 KB
- 需要 B 的 16 行:16 × 1024 × 4 = 64 KB
- 这 128 KB 可以放入 L2 Cache!
整个矩阵有 (1024/16) × (1024/16) = 4096 个子块
- A 的每行被读取 1024/16 = 64 次(分布在 64 个列方向的子块中)
- B 的每行被读取 1024/16 = 64 次(分布在 64 个行方向的子块中)
总数据传输:
- A:M × K × (N/TILE) × 4 = 1024 × 1024 × 64 × 4 = 256 MB
- B:N × K × (M/TILE) × 4 = 256 MB
- 总计:512 MB
相比朴素版本的 8 GB,减少了 16 倍!(恰好等于 TILE 大小)
图示理解
1 | |
分块的三大优势
| 优势 | 说明 |
|---|---|
| 1. 缓存命中率↑ | 小块数据能放入缓存,反复使用不被踢出 |
| 2. 内存带宽需求↓ | 总数据传输量降低 TILE 倍 |
| 3. 计算访存比↑ | 同样的数据量产生更多计算,更接近硬件算力峰值 |
在 GPU 上,分块更加关键——因为 GPU 有专门的 Shared Memory(共享内存),分块可以让数据从慢速的 Global Memory 加载到快速的 Shared Memory,大幅提升性能。这正是 CUDA 矩阵乘法优化的核心思想。
第四部分:寄存器分块——微内核设计
阅读本文以下内容前,请务必通读参考链接3[3]的文章内容,对计算内核的外积计算方式以及缓存分块技术有一定了解。
4.1 寄存器资源分析
AVX-512 提供 32 个 512-bit 的 ZMM 寄存器,每个可存储 16 个 float。微内核(micro-kernel)的目标是最大化寄存器利用率,让尽可能多的数据驻留在寄存器中。
4.2 分块尺寸推导
设微内核计算 C 的一个 MR × NR 子块:
1 | |
约束条件:
注:因为本文是基于行主序实现,所以要求
一定是16的整数倍,便于写入分块的 C[MR, NR]。
两种可行配置:
| 配置 | C 寄存器 | A | B | 临时 | 总计 | 每迭代 FMA |
|---|---|---|---|---|---|---|
| MR=30, NR=16 | 30 | 1 | 1 | 0 | 32 | 30 |
| MR=14, NR=32 | 28 | 1 | 2 | 1 | 32 | 28 |
4.3 为什么选择 MR=14, NR=32?
虽然 30×16 配置的 FMA 数量更多,但实测 14×32 性能更优,原因如下:
a. 端口竞争分析
每次 K 迭代的指令分布:
配置 30×16:
- Broadcast: 30 次 → Port 5,需要 30 cycles
- FMA: 30 次 → Port 0/1,需要 15 cycles
- Load: 1 次 → Port 2/3,需要 0.5 cycle
→ Port 5 成为瓶颈!
配置 14×32:
- Broadcast: 14 次 → Port 5,需要 14 cycles
- FMA: 28 次 → Port 0/1,需要 14 cycles
- Load: 2 次 → Port 2/3,需要 1 cycle
→ FMA 和 Broadcast 平衡!
注:此部分为claude的分析结果,Broadcast、FMA、Load的计算次数是正确的,Inst Issue Port和Latency尚未查证。
b. Cache Line 利用率
14×32 配置:
- B 每次加载 32 float = 128 bytes = 2 个完整 cache line ✓
30×16 配置:
- B 每次加载 16 float = 64 bytes = 1 个 cache line ✓
- 但 A 需要 30 float = 120 bytes,跨 2 个 cache line,可能有浪费
4.4 微内核代码实现
1 | |
4.5 外积(Rank-1 Update)的数学本质
矩阵乘法可以分解为 K 次 Rank-1 Update:
其中 ⊗ 表示外积:
外积相比内积的优势:
| 方面 | 内积 | 外积 |
|---|---|---|
| 累加器数量 | 1 个(当前 C[i,j]) | MR × NR 个(整个子块) |
| 累加器位置 | 频繁换入换出内存 | 全程驻留寄存器 |
| 单次迭代 | 计算 1 个 C 元素 | 更新 448 个 C 元素 |
| A 的复用 | 被 N 个 B 行复用(跨时间) | 被 NR 个 B 元素复用(同时) |
| B 的复用 | 无(每个 B 行只用一次) | 被 MR 个 A 元素复用(同时) |
关键区别: 内积的复用是”跨时间”的(A 行在计算多个 C 元素时被复用,但中间可能被换出 cache),外积的复用是”同时”的(A 和 B 在同一批指令中互相复用,数据就在寄存器里)。
第五部分:缓存分块——多级存储层次优化
BLIS设计示意图:
记得回忆一下参考链接3[3]中的缓存分块内容。
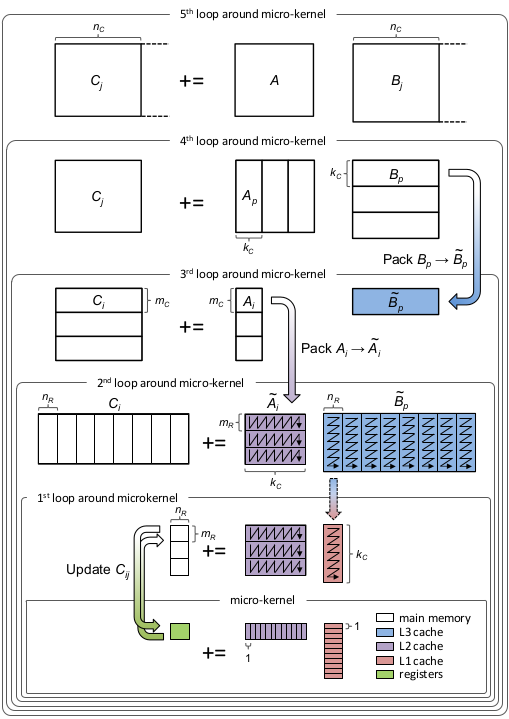
5.1 缓存层次与数据块大小
1 | |
5.2 分块参数计算
根据缓存大小反推分块参数:
约束条件:
- KC × NR × 4 ≤ L1_size (B panel 放 L1)
- MC × KC × 4 ≤ L2_size (A block 放 L2)
- NC × KC × 4 ≤ L3_size (B block 放 L3)
对于配置 MR=14, NR=32:
- KC = 384(保证 B panel 适合 L1)
- MC = 840(保证 A block 适合 L2)
- NC = 1024(保证 B block 适合 L3)
claude insight
1 | |
claude 认为前面的约束条件中:
- KC × NR × 4 ≤ L1_size / 2 (B panel 放 L1)
是比较好的工程实践,原因如下:
- A 的访问:虽然 A 主要驻留 L2,但当前 micro-kernel 正在使用的 A[MR, KC] 也会进入 L1
- 避免 cache 颠簸:如果 B panel 占满 L1,A 的访问会把 B 换出,然后 B 又把 A 换出,反复颠簸
- 安全余量:L1 cache 是组相联的,不是所有空间都能被有效利用,预留一半是工程经验值
简单来说: 除以 2 是为了给 A 和其他数据留出空间,避免 B 和 A 在 L1 中互相驱逐。
5.3 循环嵌套结构
1 | |
5.4 数据复用分析
1 | |
第六部分:数据打包(Packing)
6.1 为什么需要 Pack?
1 | |
6.2 Pack 后的内存布局
1 | |
6.3 Pack 实现
1 | |
6.4 Pack 开销分析
1 | |
第七部分:指令级并行与循环展开
7.1 FMA 指令的流水线特性
1 | |
7.2 FMA 循环展开
- 消除循环控制开销
1 | |
- 帮助编译器优化寄存器分配
1 | |
- 增加指令级并行的可见性
虽然 C[0]~C[13] 本身独立,但展开后 CPU 的调度器能更容易地同时发射多条独立指令,而不需要动态分析循环迭代间的独立性。
第八部分:多线程并行化
8.1 并行策略
1 | |
8.2 多核性能结果
测试配置:M = N = K = 4096,24 线程
| Kernel | Peak GFLOPS | Avg GFLOPS |
|---|---|---|
core_v5_parallel | 2010.61 | 1909.40 |
blas_row_AB^T | 1914.91 | 1796.69 |